k8s监控
1. 日志
1.1 为什么选择loggie?
Filebeat缺陷:
- 隔离性弱:由于所有的服务日志都会发送到全局唯一的Queue里,导致服务日志数据混在一起,在异常场景发生时,无法有隔离性的保障
- 不支持多个Output:有一些场景下,我们可能需要将不同服务的不同类型日志发送至不同的后端,但Filebeat无法使用同一个Agent去发送到不同的Kafka集群,只能在节点上部署多个Agent,导致维护和资源成本上升
- 可扩展性有限:相比Logstash/Flume等,Filebeat并非使用类似的input->queue->output的灵活多个pipeline设计,在对于日志数据的处理/过滤/增强上,依赖的是Filebeat有限的一些processor,可扩展性不足。同时Filebeat也无法作为中转聚合使用,在使用场景下大大受限,需要额外引入其他组件。另外类似日志报警等场景,Filebeat也无法满足
- 日志排障运维困境:Filebeat的metrics比较有限,很多时候我们想要排查诸如常见的日志是否有采集、采集的日志是否完整、发送是否有延迟等等排障场景,Filebeat没有提供相应的功能,十分影响线上的问题排查效率。而且Filebeat未提供Prometheus格式的监控指标,需要额外注入exporter
- 性能不够:虽然Filebeat性能尚可,但是在我们的实际使用时,遇到日志场景复杂、日志量大的情况时,存在吞吐量的瓶颈,无法满足实时性的需求。
总结一下,我们理想中的日志Agent是一个:
- 开箱即用:可快速部署容器化场景下的日志采集服务;有完善的文档与经验介绍;
- 高性能:比原生Filebeat性能高,资源占用少;
- 高可靠:隔离性稳定性更强;默认集成更多的监控指标,方便运维排障;
- 可扩展:基于微内核的架构,用户可方便快捷的写自己的插件,满足各种定制化需求;
1.2 Kubernetes下的日志采集
在传统的使用虚拟机/云主机/物理机的时代,业务进程部署在固定的节点上,业务日志直接输出到宿主机上,运维只需要手动或者使用自动化工具把日志采集Agent部署在节点上,加一下Agent的配置,就可以开始采集日志了。
而在Kubernetes环境中,情况就没这么简单了:
- 动态迁移:在Kubernetes集群中经常存在Pod主动或者被动的迁移,频繁的销毁、创建,我们无法和传统的方式一样人为的给每个服务下发日志采集配置。
- 日志存储方式多样性:容器的日志存储方式有很多不同的类型,例如stdout、hostPath、emptyDir、pv等。
- Kubernetes元信息:由于日志数据采集后会被集中存储,所以查询日志时,需要根据namespace、pod、container、node,甚至包括容器的环境变量、label等维度来检索、过滤,此时要求Agent感知并默认在日志里注入这些元信息。
1.3 Agent部署形式
采集容器日志,Agent有两种部署方式:
- DaemonSet :每个节点部署一个Agent
- Sidecar :每个Pod增加一个Sidecar容器,运行日志Agent
两种部署方式的优劣都显而易见:
- 资源占用:DaemonSet每个节点上一个,而Sidecar每个Pod里一个,容器化形态下,往往一个Node上可能会跑很多的Pod,此时DaemonSet的方式远小于Sidecar,而且节点上Pod个数越多越明显
- 侵入性:Sidecar的方式,Agent需要注入到业务Pod中,不管是否有平台封装这一过程,还是采用Kubernetes webhook的方式默认注入,仍然改变了原本的部署方式
- 稳定性:日志采集在大部分的情况下,需要保障的是稳定性,最重要的是不能影响业务,如果采用Sidecar的方式,在Agent发生异常或者oom等情况,很容易对业务容器造成影响。另外,Agent比较多的时候,在连接数等方面会对下游服务比如Kafka造成一定的隐患。
- 隔离性:DaemonSet情况下,节点所有的日志都共用同一个Agent,而Sidecar方式,只会采集同一个Pod内的业务日志,此时Sidecar的隔离性理论上会好一些
- 性能:Sidecar由于只会采集该Pod里的日志,压力相对较小,极端情况下,达到Agent的性能瓶颈比DaemonSet方式概率也会小很多
1.4 日志系统架构与演进
(1)小规模业务场景
每天的日志规模较小,比如只有几百G(预估500G以下)左右,日志的使用场景仅仅用于日常运维排查问题,可以采用Loggie直接发送至Elasticsearch集群的方式。
架构图如下所示: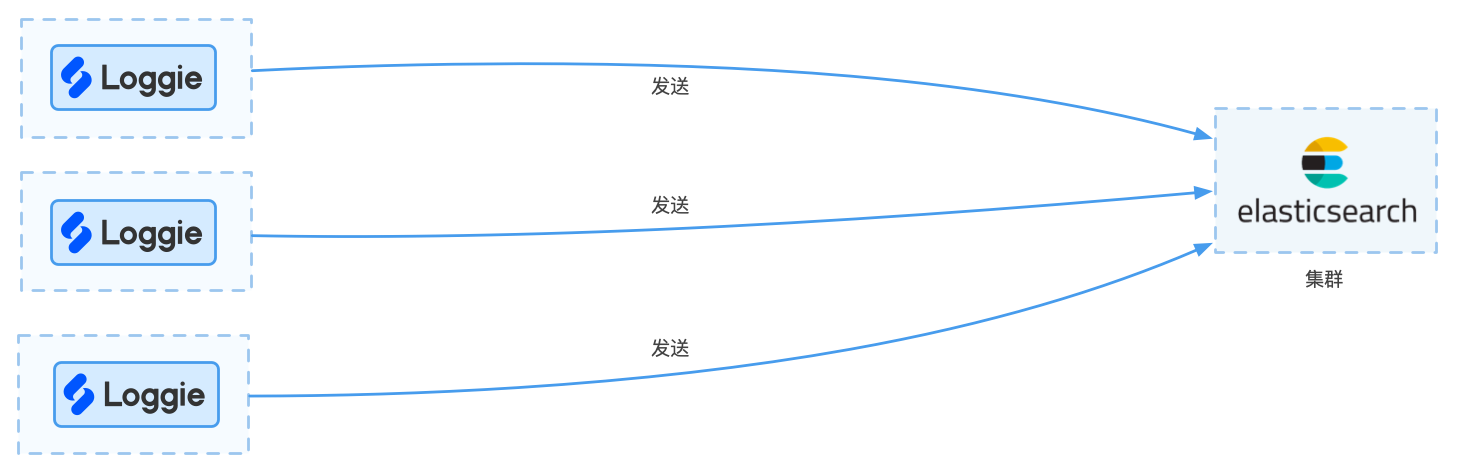
优点:
- 架构简单,便于维护
缺点:
- 由于Elasticsearch的性能有限,在日志量级突然增大时,Agent直接发送可能会导致大量的重试或者失败,导致Elasticsearch不稳定
- 可扩展性较差
变种:
因为一直以来ELK架构的流行,Elasticsearch是最常用的日志存储。
如果有其他服务对Elasticsearch的依赖,或者有Elasticsearch的运维经验,Elasticsearch是一个还不错的选择。
但是,Elasticsearch对资源和运维有一定的要求,在某些轻量级和资源敏感的环境下,可以考虑:
- 使用Loki存储
- 如果有相关的技术储备,还可以考虑发送至Clickhouse/Hive/Doris等。
(2)中型规模业务场景
在每天的日志量级稍大,比如在500G至1T的规模,架构和业务使用上有扩展性的考虑,可考虑引入Loggie中转集群。
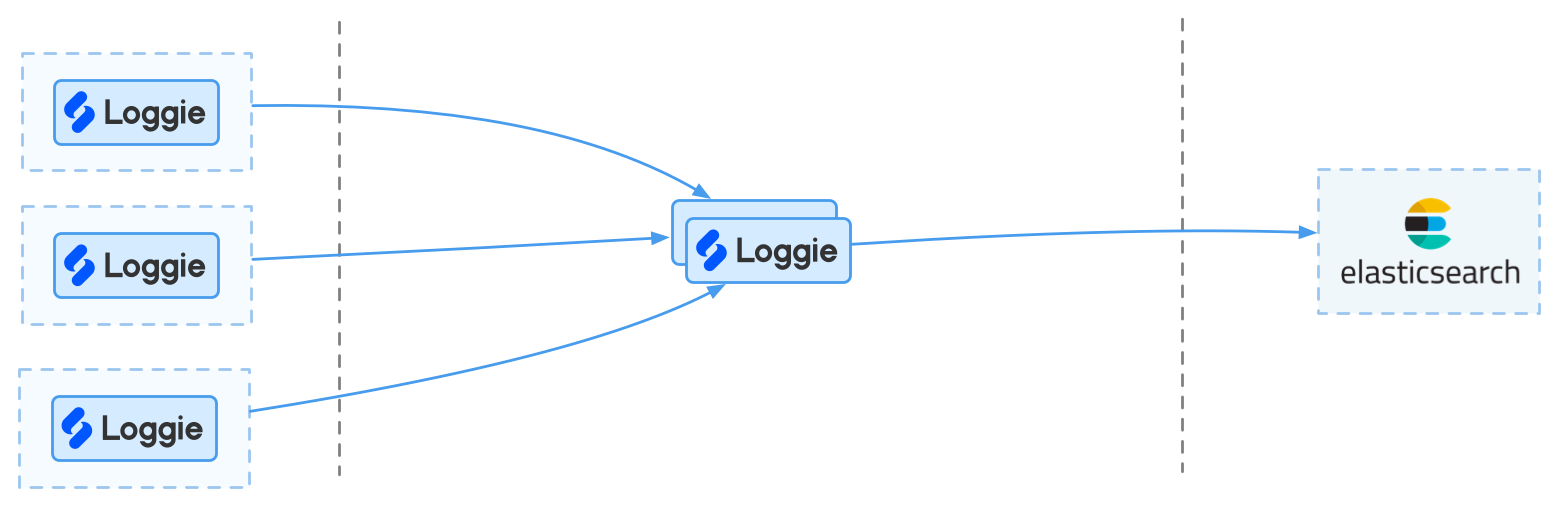
优点:
- 中转机集群可以承担日志切分等能力
- 中转机集群有一定的缓冲能力
缺点:
- 缓冲能力相比消息队列较弱
(3)大型规模业务场景
如果日志量较大,比如1T以上场景,对性能与稳定性要求比较高,可考虑使用Kafka等消息队列集群。
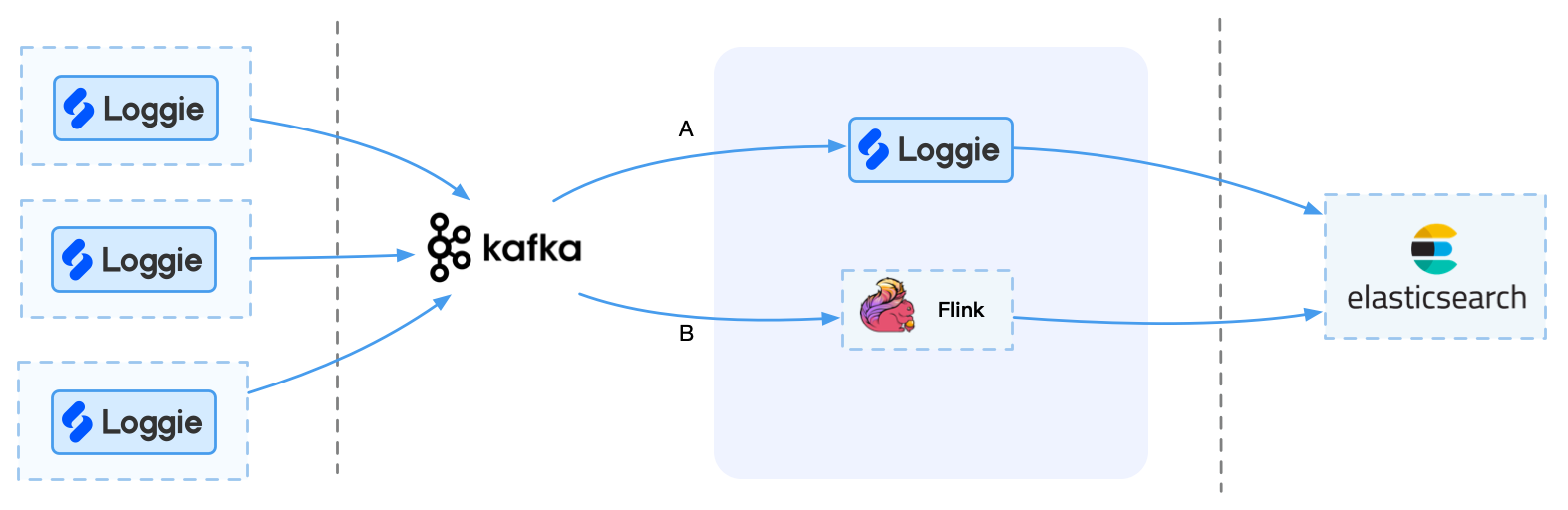
需要注意的是,Kafka本身并不能直接发送至后端,所以这里需要考虑如何将Kafka的数据实时导入到后端存储中。
这时候,我们可以选择一些组件消费Kafka,发送至后端,比如Loggie/Logstash/Kafka connect/Flink等。 但是Flink适合有自己的实时流平台或者运维能力的企业,否则可能引入更多运维成本。
优点:
- 使用消息队列比如Kafka,可以做到缓存和高峰期消峰
- 可以让更多的消费者消费Kafka,提供更多可扩展性
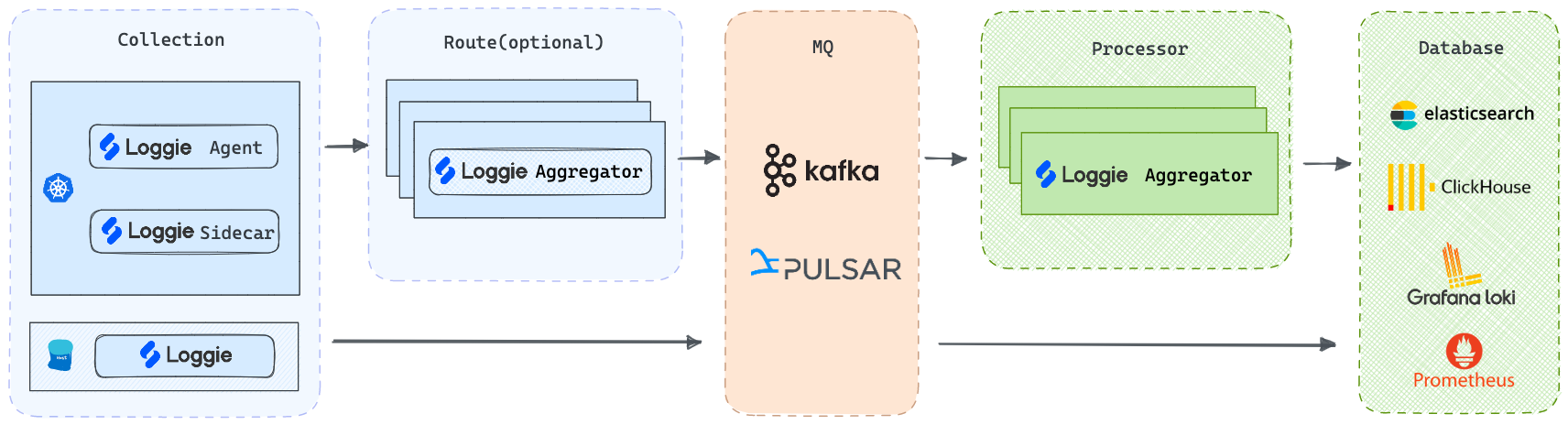
(4)超大型规模业务场景
几十TB至PB级,相比上面大规模场景,集群数量多,机房架构复杂,可以根据以上架构增加更多灵活的扩展。
比如:
- 使用Loggie的多Pipeline特性,将业务日志拆分发送至多个Kafka集群
- 在大规模架构下增加前置Loggie中转集群,提前进行分流和转发
最终我们可以基于Loggie,搭建一套生产级别的全链路日志数据平台。
1.5 日志存储选型对比
综合对比,如下:
- 存储成本:Loki存储是裸数据,经过压缩后理论上空间是最小的。ES存储内容最多,因此存储成本比较高。而Hive、ClickHouse因只有列存,相对较小(对于比较随机的纯文本数据,列存理论上和字符串压缩接近)。
- 分析能力:Hive支持完整SQL92,并且没有计算量的限制,分析能力最强。ClickHouse支持的是有限SQL集,对常见的场景足够用。接下来是ES、Loki最弱。
- 查询速度:在建立索引情况下,ES是当之无愧的王者。基于MPP引擎的ClickHouse次之(对于带计算的分析,ClickHouse是最强的)。
- 分析成本:Loki最高,读取数据后大部分工作都需要外围完成。
- 查询成本:ES读取数据量最少,因此最优,接下来是ClickHouse,Hive和Loki。
2. Prometheus
2.x 长尾问题
使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。
irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。
rate、irate、increase
rate()
此函数计算整个采样周期内每秒的增长率。
例如:rate(http_requests_total[5m]) 得出的是HTTP在5分钟窗口内,平均每秒的请求率。作为最常见的函数,它以可预测的每秒输出单位产生平滑的rate。
irate()
即 “瞬时rate”,此函数和rate()一样,计算每秒的增长率,但只对规定采样周期内的最后两个样本进行计算,而忽略前面所有样本。
例如:irate(http_requests_total[5m]) 选取规定5分钟窗口内的最后两个样本,并计算两者之间每秒的增长率。如果想让一个放大的图形显示出对rate变化的快速响应,那这个函数就很有用,它呈现的结果会比rate()的有更多的峰值。
increase()
此函数和 rate() 完全一样,只是它没有将最终单位转换为 “每秒”(1/s)。每个规定的采样周期就是它的最终单位。
例如:increase(http_requests_total[5m]) 得出的是5分钟的采样周期内处理完成的HTTP请求的总增长量(单位1/5m)。因此increase(foo[5m])/ (5 * 60) 等同于rate(foo[5m])。
这三个函数都有一个共同的要求,就是它们在规定的采样周期中都需要有至少两个样本才能运行。少于两个样本的序列将从结果中删除。
2.x Pull vs Push
(1)介绍
pull模式:客户端使用library,变成exporter,然后prometheus server定时从exporter pull数据。
push模式:使用pushgateway,所有客户端push数据到pushgateway,然后prometheus server定时从pushgateway pull数据。
(2)对比
push模式的缺点:采用pushgateway的方式,如果某一个上报方挂了,pushgateway无法感知上报方的状态,所以这时候如果不做任何操作,那么prometheus依旧会从pushgateway中获取到旧的、不正确的数据。
pull的优点:采用exporter的方式,如果某一个exporter挂掉了,那么prometheus就pull不到数据,那么时序数据库没有新的数据产生。这是正确的。
所以pull模式是prometheus的推荐模式。
(3)数据时间戳
Pushgateway拒绝任何带有时间戳的推送,因为他pull抓取信息的时候会自己给信息加上时间戳。而exporter方式可以通过honor_timestamps配置来让Prometheus选择是否使用拉取数据中的时间戳。
2.x Alertmanager告警抑制功能较弱
告警抑制的实现也是基于labels,但是是基于全局的,不是特定路由,而且只支持静态label,这个地方的设计其实不太好,有两个问题:
- 全局容易出现不同用户的规则互相影响,为了减少此种行为的发生,我们应该为每个路由设定一个抑制规则,同时必须包含路由的labels
- 静态label对label规范化增加了不必要的限制,所有数据都必须拥有指定的抑制labels才能使用
2.x Prometheus存储
(1)本地存储
当前样本数据所在的块会被直接保存在内存中,不会持久化到磁盘中。为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))重新记录,从而恢复数据。
本地存储不可复制,无法构建集群,如果本地磁盘或节点出现故障,存储将无法扩展和迁移。因此我们只能把本地存储视为近期数据的短暂滑动窗口。如果你对数据持久化的要求不是很严格,可以使用本地磁盘存储多达数年的数据。
2.x Prometheus高可用
prometheus 高可用有几种方案:
- 1.基本 HA:即两套 prometheus 采集完全一样的数据,外边挂负载均衡
- 2.HA + 远程存储:除了基础的多副本prometheus,还通过Remote write 写入到远程存储,解决存储持久化问题
- 3.联邦集群:即federation,按照功能进行分区,不同的 shard 采集不同的数据,由Global节点来统一存放,解决监控数据规模的问题。
- 4.使用thanos 或者victoriametrics,来解决全局查询、多副本数据 join 问题。
就算使用官方建议的多副本 + 联邦,由于prometheus的本地存储没有数据同步能力,要在保证可用性的前提下,再保持数据一致性是比较困难的,基础的 HA proxy 满足不了要求,比如:
- 集群的后端有 A 和 B 两个实例,A 和 B 之间没有数据同步。A 宕机一段时间,丢失了一部分数据,如果负载均衡正常轮询,请求打到A 上时,数据就会异常。
- 如果 A 和 B 的启动时间不同,时钟不同,那么采集同样的数据时间戳也不同,就不是多副本同样数据的概念了
- 就算用了远程存储,A 和 B 不能推送到同一个 tsdb,如果每人推送自己的 tsdb,数据查询走哪边就是问题了。
因此解决方案是在存储、查询两个角度上保证数据的一致:
- 存储角度:如果使用 remote write 远程存储, A 和 B后面可以都加一个 adapter,adapter做选主逻辑,只有一份数据能推送到 tsdb,这样可以保证一个异常,另一个也能推送成功,数据不丢,同时远程存储只有一份,是共享数据。方案可以参考这篇文章
- 查询角度:上边的方案实现很复杂且有一定风险,因此现在的大多数方案在查询层面做文章,比如thanos 或者victoriametrics,仍然是两份数据,但是查询时做数据去重和join。只是 thanos是通过 sidecar 把数据放在对象存储,victoriametrics是把数据remote write 到自己的 server 实例,但查询层 thanos-query 和victor的 promxy的逻辑基本一致。
我们采用了thanos来支持多地域监控数据,具体方案可以看https://xie.infoq.cn/article/e723b90fabb9b00437d0de96b
参考文档
(1)高可用prometheus常见问题:https://yasongxu.gitbook.io/container-monitor/yi-.-kai-yuan-fang-an/di-2-zhang-prometheus/prometheus-use