Sql优化
1、 分库
分库 就是将数据库中的数据分散到不同的数据库上,可以垂直分库,也可以水平分库。
垂直分库 就是把单一数据库按照业务进行划分,不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。例如:说你将数据库中的用户表、订单表和商品表分别单独拆分为用户数据库、订单数据库和商品数据库。
水平分库 是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,这样就实现了水平扩展,解决了单表的存储和性能瓶颈的问题。例如:订单表数据量太大,你对订单表进行了水平切分(水平分表),然后将切分后的 2 张订单表分别放在两个不同的数据库。
##2、分表
分表 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
垂直分表 是对数据表列的拆分,把一张列比较多的表拆分为多张表。例如:我们可以将用户信息表中的一些列单独抽出来作为一个表。
水平分表 是对数据表行的拆分,把一张行比较多的表拆分为多张表,可以解决单一表数据量过大的问题。例如:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
##3、分库分表场景
- 单表的数据达到千万级别以上,数据库读写速度比较缓慢。
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
- 应用的并发量太大。
##4、分库分表引入的问题
- join 操作
- 事务问题
- 分布式 ID
- 跨库聚合查询问题
- ……
##5、分库分表后的数据迁移
(1)停机更新
(2)增量迁移
(3)双写
##6、MySQL Online DDL
MySQL 的 DDL 有很多种方法。
MySQL 本身自带三种方法,分别是:copy、inplace、instant。
copy 算法为最古老的算法,在 MySQL 5.5 及以下为默认算法。MySQL 会建立一个新的临时表,把源表的所有数据写入到临时表,在此期间无法对源表进行数据写入。MySQL 在完成临时表的写入之后,用临时表替换掉源表。这个算法主要被早期(<=5.5)版本所使用。
从 MySQL 5.6 开始,引入了 inplace 算法并且默认使用。inplace 算法还包含两种类型:rebuild-table 和 not-rebuild-table。MySQL 使用 inplace 算法时,会自动判断,能使用 not-rebuild-table 的情况下会尽量使用,不能的时候才会使用 rebuild-table。当 DDL 涉及到主键和全文索引相关的操作时,无法使用 not-rebuild-table,必须使用 rebuild-table。其他情况下都会使用 not-rebuild-table。
nplace 算法的操作阶段主要分为三个:
- Prepare阶段: - 创建新的临时 frm 文件(与 InnoDB 无关)。 - 持有 EXCLUSIVE-MDL 锁,禁止读写。 - 根据 alter 类型,确定执行方式(copy,online-rebuild,online-not-rebuild)。 更新数据字典的内存对象。 - 分配 row_log 对象记录数据变更的增量(仅 rebuild 类型需要)。 - 生成新的临时ibd文件 new_table(仅rebuild类型需要)。
- Execute 阶段:
- 降级EXCLUSIVE-MDL锁,允许读写。
- 扫描old_table聚集索引(主键)中的每一条记录 rec。
- 遍历new_table的聚集索引和二级索引,逐一处理。
- 根据 rec 构造对应的索引项。
- 将构造索引项插入 sort_buffer 块排序。
- 将 sort_buffer 块更新到 new_table 的索引上。
- 记录 online-ddl 执行过程中产生的增量(仅 rebuild 类型需要)。
- 重放 row_log 中的操作到 new_table 的索引上(not-rebuild 数据是在原表上更新)。
- 重放 row_log 中的DML操作到 new_table 的数据行上。
- Commit阶段:
- 当前 Block 为 row_log 最后一个时,禁止读写,升级到 EXCLUSIVE-MDL 锁。
- 重做 row_log 中最后一部分增量。
- 更新 innodb 的数据字典表。
- 提交事务(刷事务的 redo 日志)。
- 修改统计信息。
- rename 临时 ibd 文件,frm文件。
- 变更完成,释放 EXCLUSIVE-MDL 锁。
从 MySQL 8.0.12 开始,引入了 instant 算法并且默认使用。目前 instant 算法只支持增加列等少量 DDL 类型的操作(可以直接修改表的 metadata 数据,省掉了 rebuild 的过程,极大的缩短了 DDL 语句的执行时间),其他类型仍然会默认使用 inplace。
有一些第三方工具也可以实现 DDL 操作,最常见的是 percona 的 pt-online-schema-change 工具(简称为 pt-osc),和 github 的 gh-ost 工具,均支持 MySQL 5.5 以上的版本。
需要注意以下几个方面:
(1)负载
所有方式对大表做 DDL 都会增加负载,只是程度的不同,主要为 IO 的负载。如果是 IO 使用非常高的实例,建议在 IO 较小的时间段执行 DDL 操作。
(2)额外空间占用
copy、inplace rebuild-table、gh-ost、pt-online-schema-change,都会将表完整复制一份出来再做 DDL 变更,因此会使用和原表空间一样大(甚至更大,如果是加列的操作的话)的额外空间,另外还会生成大量的临时日志。要特别注意剩余空间,确保空间充裕,不然可能导致 DDL 过程中磁盘写满。
(3)主从同步延时
所有方式做 DDL 均会引发主从同步延时。其中 copy 和 inplace 算法,只有主完成了 DDL 操作之后,binlog 才会同步给从库,从库才能开始操作 DDL,从库操作完 DDL 之后才能开始操作其他语句,因此会造成巨大的(大概两倍 DDL 操作时间)的延时。其他方法产生的延时较小,但仍然可能有几秒的延时。
(4)MDL
所有方式做 DDL 均会产生 MDL(metadata lock)。除了 copy 模式会有持续性的锁(DDL 的整个过程期间无法向该表写入任何数据)之外,其他方式的 MDL 均为短暂的锁。
除了 copy 模式之外的所有模式,MDL 如下:
- 在 DDL 的开始阶段,申请该表的 EXCLUSIVE-MDL 锁,禁止读写
- 降级 EXCLUSIVE-MDL 锁,允许读写
- 在 DDL 的最终 COMMIT 阶段,升级 EXCLUSIVE-MDL 锁,禁止读写
其中的阶段一和阶段三,其 MDL 的持续时间都是非常短暂的,也就是申请到了 MDL 锁之后会在很快的时间(一般小于一秒)处理完成相关操作并释放锁,一般情况下是不会影响业务的。只有阶段二是真正在处理数据,持续时间一般较长。
但是,有可能出现在阶段一和阶段三,无法申请到 MDL 的情况。这是因为 MDL 和所有的读写语句都可能会产生冲突,如果是在申请 MDL 的时候,之前有读写的事务一直没有执行完成(或者执行完成之后一直没有 COMMIT),MDL 就会无法立刻申请到,这个时候,DDL 语句,以及所有在该 DDL 语句之后的读写事务,都会阻塞并等待之前的读写事务完成,导致整个实例处于不可用状态。这个时候 SHOW PROCESSLIST 看到的语句状态为 waiting for metadata lock。
(5)其他
MySQL 的 inplace 算法虽然支持在 DDL 过程中间的读写,但是对写入的数据量有上限,不能超过 innodb_online_alter_log_max_size(默认为 128M)。如果超过上限可能导致执行失败。
7、尽量设置字段为not null
(1)聚合函数不准确
对于NULL值的列,使用聚合函数的时候会忽略NULL值。
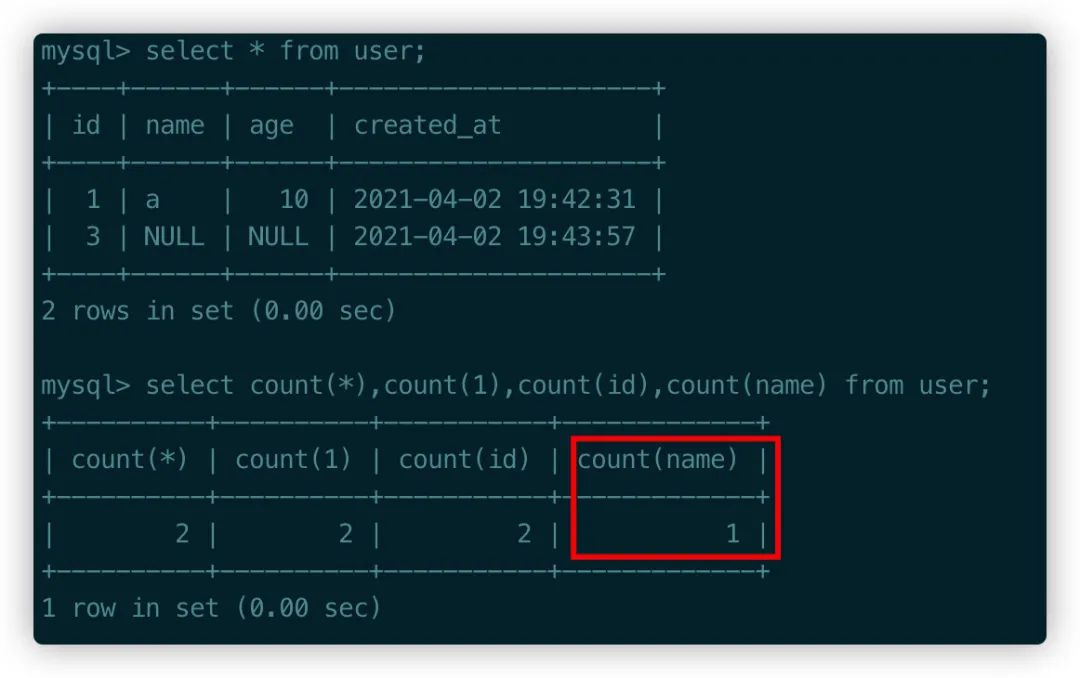
(2)对于NULL值的列,是不能使用=表达式进行判断的,下面对name的查询是不成立的,必须使用is NULL。
(3)NULL和其他任何值进行运算都是NULL,包括表达式的值也是NULL。
user表第二条记录age是NULL,所以+1之后还是NULL,name是NULL,进行concat运算之后结果还是NULL。
(4)对于distinct和group by来说,所有的NULL值都会被视为相等,对于order by来说升序NULL会排在最前
(5)索引列存在NULL会导致优化器在做索引选择的时候更复杂,更加难以优化。~~(MySQL版本已优化)
## 8、MySQL in vs exists(版本优化已趋于接近,讨论无意义)
- IN查询在内部表和外部表上都可以使用到索引;- Exists查询仅在内部表上可以使用到索引;- 当子查询结果集很大,而外部表较小的时候,Exists的Block Nested Loop(Block 嵌套循环)的作用开始显现,并弥补外部表无法用到索引的缺陷,查询效率会优于IN。- 当子查询结果集较小,而外部表很大的时候,Exists的Block嵌套循环优化效果不明显,IN 的外表索引优势占主要作用,此时IN的查询效率会优于Exists。
8、SQL优化
总结到 SQL 优化中,就如下三点:
- 最大化利用索引。
- 尽可能避免全表扫描。
- 减少无效数据的查询。
参考资料
2、100亿数据平滑数据迁移,不影响服务:https://www.w3cschool.cn/architectroad/architectroad-data-smooth-migration.html
3、MySQL 5.7 特性:Online DDL:https://cloud.tencent.com/developer/article/1697076
4、为什么数据库字段要使用NOT NULL:https://cloud.tencent.com/developer/article/1812479